Debian a Problem Has Ocurred and the Systems Cant Recover Please Log Our and Try Again
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Troubleshoot Azure-to-Azure VM replication errors
This article describes how to troubleshoot common errors in Azure Site Recovery during replication and recovery of Azure virtual machines (VM) from one region to another. For more information about supported configurations, see the support matrix for replicating Azure VMs.
Azure resource quota issues (error lawmaking 150097)
Make certain your subscription is enabled to create Azure VMs in the target region that you program to use as your disaster recovery (DR) region. Your subscription needs sufficient quota to create VMs of the necessary sizes. By default, Site Recovery chooses a target VM size that's the same as the source VM size. If the matching size isn't bachelor, Site Recovery automatically chooses the closest available size.
If there's no size that supports the source VM configuration, the following message is displayed:
Replication couldn't be enabled for the virtual machine <VmName>. Possible causes
- Your subscription ID isn't enabled to create whatever VMs in the target region location.
- Your subscription ID isn't enabled, or doesn't have sufficient quota, to create specific VM sizes in the target region location.
- No suitable target VM size is found to match the source VM's network interface carte du jour (NIC) count (two), for the subscription ID in the target region location.
Fix the problem
Contact Azure billing support to enable your subscription to create VMs of the required sizes in the target location. So retry the failed operation.
If the target location has a capacity constraint, disable replication to that location. Then, enable replication to a dissimilar location where your subscription has sufficient quota to create VMs of the required sizes.
Trusted root certificates (fault code 151066)
If not all the latest trusted root certificates are present on the VM, your task to enable replication for Site Recovery might neglect. Hallmark and authorization of Site Recovery service calls from the VM fail without these certificates.
If the enable replication job fails, the following message is displayed:
Site Recovery configuration failed. Possible cause
The trusted root certificates required for potency and hallmark aren't nowadays on the virtual machine.
Fix the problem
Windows
For a VM running the Windows operating organisation, install the latest Windows updates and so that all the trusted root certificates are present on the VM. Follow the typical Windows update management or certificate update management process in your organization to go the latest root certificates and the updated certificate revocation list on the VMs.
- If yous're in a disconnected environs, follow the standard Windows update process in your organization to get the certificates.
- If the required certificates aren't present on the VM, the calls to the Site Recovery service fail for security reasons.
To verify that the effect is resolved, become to login.microsoftonline.com from a browser in your VM.
For more information, run across Configure trusted roots and disallowed certificates.
Linux
Follow the guidance provided past the distributor of your Linux operating organization version to become the latest trusted root certificates and the latest certificate revocation list on the VM.
Because SUSE Linux uses symbolic links, or symlinks, to maintain a certificate list, follow these steps:
-
Sign in as a root user. The hash symbol (
#) is the default command prompt. -
To modify the directory, run this control:
cd /etc/ssl/certs -
Check whether the Symantec root CA certificate is present:
ls VeriSign_Class_3_Public_Primary_Certification_Authority_G5.pem-
If the Symantec root CA document isn't found, run the post-obit control to download the file. Check for whatever errors and follow recommended actions for network failures.
wget https://docs.broadcom.com/docs-and-downloads/content/dam/symantec/docs/other-resources/verisign-grade-3-public-chief-certification-potency-g5-en.pem -O VeriSign_Class_3_Public_Primary_Certification_Authority_G5.pem
-
-
Check whether the Baltimore root CA document is present:
ls Baltimore_CyberTrust_Root.pem-
If the Baltimore root CA certificate isn't constitute, run this command to download the certificate:
wget https://www.digicert.com/CACerts/BaltimoreCyberTrustRoot.crt.pem -O Baltimore_CyberTrust_Root.pem
-
-
Check whether the DigiCert_Global_Root_CA certificate is present:
ls DigiCert_Global_Root_CA.pem-
If the DigiCert_Global_Root_CA isn't plant, run the post-obit commands to download the certificate:
wget http://www.digicert.com/CACerts/DigiCertGlobalRootCA.crt openssl x509 -in DigiCertGlobalRootCA.crt -inform der -outform pem -out DigiCert_Global_Root_CA.pem
-
-
To update the certificate subject hashes for the newly downloaded certificates, run the rehash script:
c_rehash -
To cheque whether the field of study hashes as symlinks were created for the certificates, run these commands:
ls -l | grep Baltimorelrwxrwxrwx 1 root root 29 Jan 8 09:48 3ad48a91.0 -> Baltimore_CyberTrust_Root.pem -rw-r--r-- 1 root root 1303 Jun v 2022 Baltimore_CyberTrust_Root.pemls -l | grep VeriSign_Class_3_Public_Primary_Certification_Authority_G5-rw-r--r-- 1 root root 1774 Jun five 2022 VeriSign_Class_3_Public_Primary_Certification_Authority_G5.pem lrwxrwxrwx 1 root root 62 Jan 8 09:48 facacbc6.0 -> VeriSign_Class_3_Public_Primary_Certification_Authority_G5.pemls -l | grep DigiCert_Global_Rootlrwxrwxrwx i root root 27 Jan 8 09:48 399e7759.0 -> DigiCert_Global_Root_CA.pem -rw-r--r-- 1 root root 1380 Jun five 2022 DigiCert_Global_Root_CA.pem -
Create a copy of the file VeriSign_Class_3_Public_Primary_Certification_Authority_G5.pem with filename b204d74a.0:
cp VeriSign_Class_3_Public_Primary_Certification_Authority_G5.pem b204d74a.0 -
Create a copy of the file Baltimore_CyberTrust_Root.pem with filename 653b494a.0:
cp Baltimore_CyberTrust_Root.pem 653b494a.0 -
Create a copy of the file DigiCert_Global_Root_CA.pem with filename 3513523f.0:
cp DigiCert_Global_Root_CA.pem 3513523f.0 -
Check that the files are present:
ls -l 653b494a.0 b204d74a.0 3513523f.0-rw-r--r-- ane root root 1774 Jan 8 09:52 3513523f.0 -rw-r--r-- 1 root root 1303 January 8 09:52 653b494a.0 -rw-r--r-- 1 root root 1774 Jan 8 09:52 b204d74a.0
Outbound URLs or IP ranges (error code 151037 or 151072)
For Site Recovery replication to work, outbound connectivity to specific URLs is required from the VM. If your VM is behind a firewall or uses network security group (NSG) rules to control outbound connectivity, y'all might face one of these issues. While we continue to support outbound admission via URLs, using an allow list of IP ranges is no longer supported.
Possible causes
- A connection can't exist established to Site Recovery endpoints because of a Domain Proper name Organization (DNS) resolution failure.
- This problem is more common during reprotection when you have failed over the virtual car but the DNS server isn't reachable from the disaster recovery (DR) region.
Fix the problem
If you're using custom DNS, brand sure that the DNS server is accessible from the disaster recovery region.
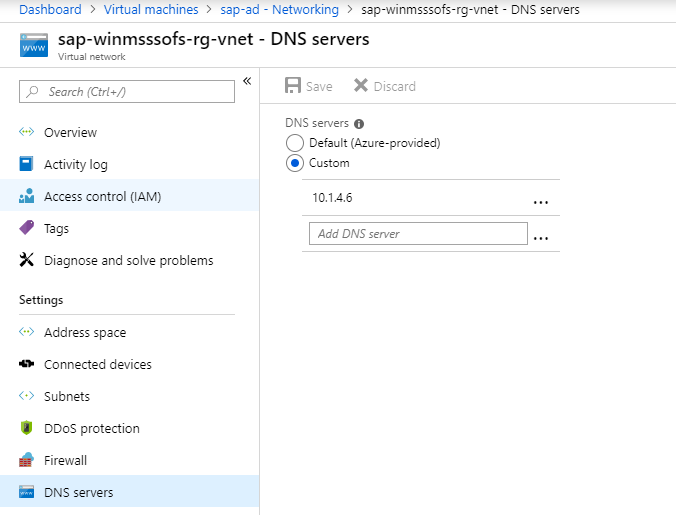
To check if the VM uses a custom DNS setting:
- Open Virtual machines and select the VM.
- Navigate to the VMs Settings and select Networking.
- In Virtual network/subnet, select the link to open the virtual network's resource page.
- Go to Settings and select DNS servers.
Try to admission the DNS server from the virtual automobile. If the DNS server isn't accessible, make it accessible by either failing over the DNS server or creating the line of site betwixt DR network and DNS.
Note
If you use individual endpoints, ensure that the VMs can resolve the private DNS records.
Effect 2: Site Recovery configuration failed (151196)
Possible cause
A connection can't be established to Microsoft 365 hallmark and identity IP4 endpoints.
Fix the problem
Azure Site Recovery required access to Microsoft 365 IP ranges for authentication. If yous're using Azure Network Security Group (NSG) rules/firewall proxy to control outbound network connectivity on the VM, ensure that you utilize Azure Active Directory (AAD) service tag based NSG rule for assuasive access to AAD. We no longer support IP address-based NSG rules.
Outcome 3: Site Recovery configuration failed (151197)
Possible cause
A connection can't be established to Azure Site Recovery service endpoints.
Fix the problem
If y'all're using Azure Network Security Group (NSG) rules/firewall proxy to command outbound network connectivity on the VM, ensure that you use service tags. We no longer support using an permit list of IP addresses via NSGs for Azure Site Recovery.
Effect 4: Replication fails when network traffic uses on-premises proxy server (151072)
Possible crusade
The custom proxy settings are invalid and the Mobility service agent didn't autodetect the proxy settings from Net Explorer (IE).
Gear up the problem
-
The Mobility service agent detects the proxy settings from IE on Windows and
/etc/environmenton Linux. -
If you adopt to set proxy only for the Mobility service, and then you can provide the proxy details in ProxyInfo.conf located at:
- Linux:
/usr/local/InMage/config/ - Windows:
C:\ProgramData\Microsoft Azure Site Recovery\Config
- Linux:
-
The ProxyInfo.conf should accept the proxy settings in the following INI format.
[proxy] Address=http://i.2.3.4 Port=567
Note
The Mobility service amanuensis just supports unauthenticated proxies.
More information
To specify the required URLs or the required IP ranges, follow the guidance in Most networking in Azure to Azure replication.
Disk not plant in VM (mistake code 150039)
A new disk attached to the VM must be initialized. If the disk isn't found, the following message is displayed:
Azure data disk <DiskName> <DiskURI> with logical unit number <LUN> <LUNValue> was non mapped to a respective disk being reported from within the VM that has the same LUN value. Possible causes
- A new data disk was attached to the VM but wasn't initialized.
- The data deejay inside the VM isn't correctly reporting the logical unit number (LUN) value at which the deejay was attached to the VM.
Fix the problem
Brand certain that the data disks are initialized, and then retry the operation.
- Windows: Attach and initialize a new disk.
- Linux: Initialize a new data disk in Linux.
If the problem persists, contact support.
Multiple disks available for protection (error code 153039)
Possible causes
- I or more disks were recently added to the virtual machine later on protection.
- One or more disks were initialized afterwards protection of the virtual machine.
Ready the trouble
To make the replication status of the VM good for you again, yous can choose either to protect the disks or to dismiss the warning.
To protect the disks
-
Go to Replicated Items > VM name > Disks.
-
Select the unprotected disk, and then select Enable replication:

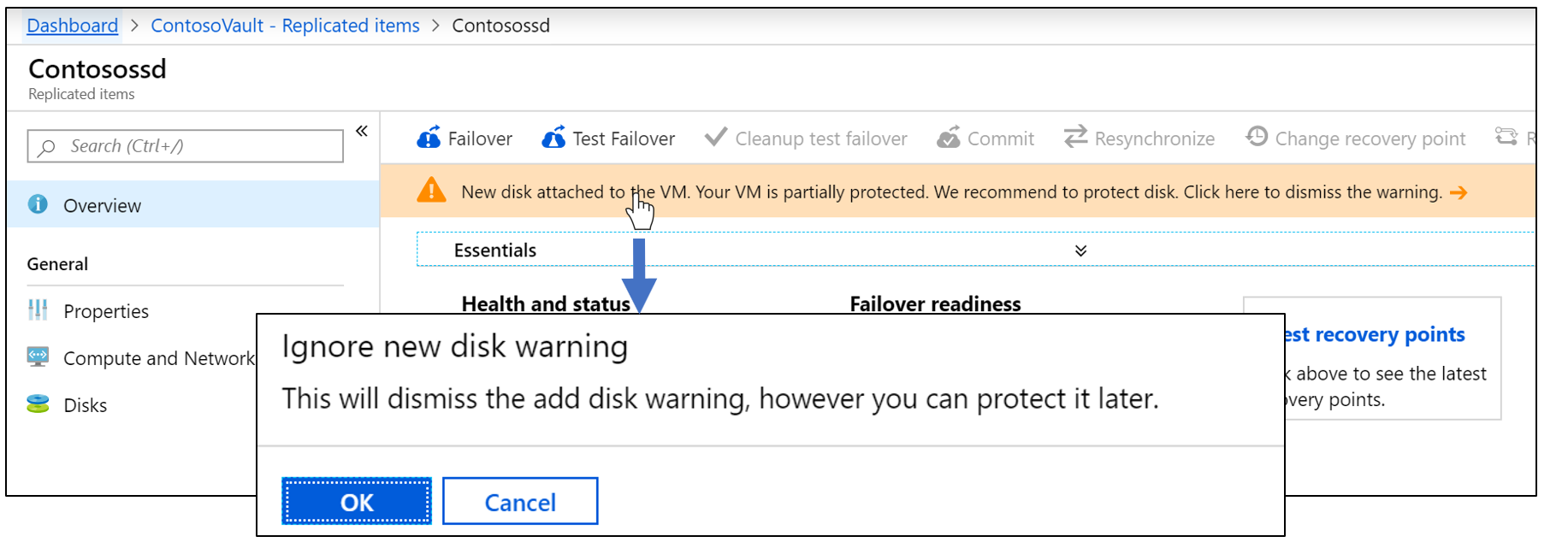
To dismiss the alert
-
Become to Replicated items > VM proper noun.
-
Select the alarm in the Overview section, then select OK.
VM removed from vault completed with data (mistake code 150225)
When Site Recovery protects the virtual machine, it creates links on the source virtual machine. When y'all remove the protection or disable replication, Site Recovery removes these links as a office of the cleanup job. If the virtual machine has a resource lock, the cleanup job gets completed with the information. The information says that the virtual automobile has been removed from the Recovery Services vault, but that some of the stale links couldn't be cleaned upwardly on the source motorcar.
Y'all can ignore this alarm if you never intend to protect this virtual car again. Merely if you accept to protect this virtual car afterward, follow the steps in this section to clean up the links.
Warning
If you don't practice the cleanup:
- When y'all enable replication by means of the Recovery Services vault, the virtual machine won't exist listed.
- If you try to protect the VM by using Virtual automobile > Settings > Disaster Recovery, the operation will neglect with the message Replication cannot be enabled considering of the existing stale resources links on the VM.
Fix the trouble
Note
Site Recovery doesn't delete the source virtual machine or affect information technology in any way while y'all perform these steps.
-
Remove the lock from the VM or VM resource group. For example, in the following image, the resource lock on the VM named
MoveDemomust exist deleted:
-
Download the script to remove a dried Site Recovery configuration.
-
Run the script, Cleanup-stale-asr-config-Azure-VM.ps1. Provide the Subscription ID, VM Resource Group, and VM name as parameters.
-
If yous're prompted for Azure credentials, provide them. Then verify that the script runs without any failures.
Replication not enabled on VM with stale resources (error lawmaking 150226)
Possible causes
The virtual motorcar has a stale configuration from previous Site Recovery protection.
A stale configuration can occur on an Azure VM if you lot enabled replication for the Azure VM by using Site Recovery, and then:
- You disabled replication, but the source VM had a resources lock.
- You deleted the Site Recovery vault without explicitly disabling replication on the VM.
- You deleted the resource group containing the Site Recovery vault without explicitly disabling replication on the VM.
Ready the problem
Notation
Site Recovery doesn't delete the source virtual motorcar or affect it in whatsoever way while you perform these steps.
-
Remove the lock from the VM or VM resources grouping. For example, in the following image, the resource lock on the VM named
MoveDemomust exist deleted: -
Download the script to remove a stale Site Recovery configuration.
-
Run the script, Cleanup-stale-asr-config-Azure-VM.ps1. Provide the Subscription ID, VM Resources Group, and VM proper noun as parameters.
-
If you're prompted for Azure credentials, provide them. Then verify that the script runs without any failures.
Tin can't select VM or resource group in enable replication chore
Issue 1: The resource group and source VM are in different locations
Site Recovery currently requires the source region resources group and virtual machines to be in the same location. If they aren't, you won't be able to find the virtual motorcar or resource group when you try to apply protection.
As a workaround, you can enable replication from the VM instead of the Recovery Services vault. Go to Source VM > Properties > Disaster Recovery and enable the replication.
Result 2: The resource group isn't part of the selected subscription
Y'all might non be able to observe the resource group at the time of protection if the resources group isn't part of the selected subscription. Make sure that the resource group belongs to the subscription that you're using.
Issue iii: Stale configuration
You might not see the VM that you want to enable for replication if a stale Site Recovery configuration exists on the Azure VM. This condition could occur if you enabled replication for the Azure VM past using Site Recovery, and then:
- You deleted the Site Recovery vault without explicitly disabling replication on the VM.
- Y'all deleted the resources grouping containing the Site Recovery vault without explicitly disabling replication on the VM.
- You lot disabled replication, but the source VM had a resource lock.
Set up the problem
Note
Make certain to update the AzureRM.Resources module before using the script mentioned in this section. Site Recovery doesn't delete the source virtual machine or bear on information technology in any way while you lot perform these steps.
-
Remove the lock, if any, from the VM or VM resource group. For example, in the following image, the resources lock on the VM named
MoveDemomust be deleted: -
Download the script to remove a stale Site Recovery configuration.
-
Run the script, Cleanup-stale-asr-config-Azure-VM.ps1. Provide the Subscription ID, VM Resource Group, and VM name equally parameters.
-
If you're prompted for Azure credentials, provide them. So verify that the script runs without any failures.
Unable to select a VM for protection
Possible cause
The virtual machine has an extension installed in a failed or unresponsive country
Fix the problem
Go to Virtual machines > Settings > Extensions and bank check for any extensions in a failed state. Uninstall whatever failed extension, and and then effort once more to protect the virtual car.
VM provisioning state isn't valid (error code 150019)
To enable replication on the VM, its provisioning state must be Succeeded. Perform the following steps to cheque the provisioning state:
- In the Azure portal, select the Resource Explorer from All Services.
- Expand the Subscriptions list and select your subscription.
- Expand the ResourceGroups list and select the resources group of the VM.
- Expand the Resource list and select your VM.
- Check the provisioningState field in the instance view on the right side.
Fix the trouble
- If the provisioningState is Failed, contact support with details to troubleshoot.
- If the provisioningState is Updating, another extension might be being deployed. Check whether there are any ongoing operations on the VM, await for them to stop, and then retry the failed Site Recovery chore to enable replication.
Unable to select target VM
Issue 1: VM is attached to a network that's already mapped to a target network
During disaster recovery configuration, if the source VM is part of a virtual network, and another VM from the same virtual network is already mapped with a network in the target resources group, the network selection drop-downward list box is unavailable (appears dimmed) by default.

Consequence 2: You previously protected the VM and and then you disabled the replication
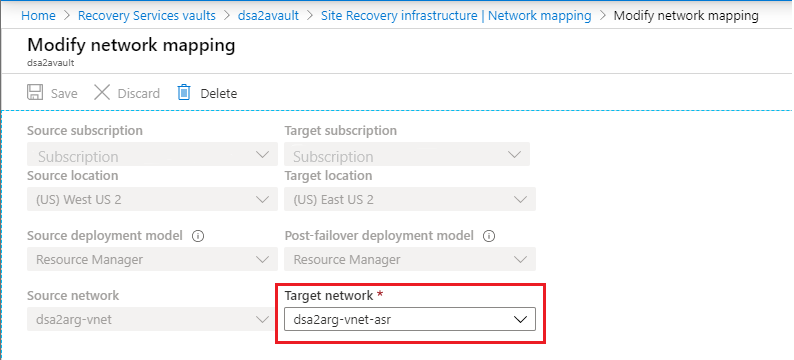
Disabling replication of a VM doesn't delete the network mapping. The mapping must exist deleted from the Recovery Services vault where the VM was protected. Select the Recovery Services vault and go to Manage > Site Recovery Infrastructure > For Azure virtual machines > Network Mapping.

The target network that was configured during the disaster recovery setup can exist changed subsequently the initial setup, and after the VM is protected. To Modify network mapping select the network name:
When the COM+ or Volume Shadow Copy Service (VSS) error occurs, the following bulletin is displayed:
Site Recovery extension failed to install. Possible causes
- The COM+ System Application service is disabled.
- The Volume Shadow Copy Service is disabled.
Fix the trouble
Set the COM+ System Awarding and Volume Shadow Copy Service to automated or manual startup manner.
-
Open up the Services panel in Windows.
-
Make sure the COM+ Arrangement Application and Volume Shadow Copy Service aren't set to Disabled equally their Startup Type.

Unsupported managed-disk size (error code 150172)
When this mistake occurs, the post-obit message is displayed:
Protection couldn't exist enabled for the virtual car as it has <DiskName> with size <DiskSize> that is bottom than the minimum supported size 1024 MB. Possible cause
The disk is smaller than the supported size of 1024 MB.
Set the problem
Make sure that the deejay size is within the supported size range, and so retry the operation.
Protection not enabled when GRUB uses device name (error code 151126)
Possible causes
The Linux Grand Unified Bootloader (GRUB) configuration files (/boot/grub/menu.lst, /boot/grub/grub.cfg, /boot/grub2/grub.cfg, or /etc/default/grub) might specify the actual device names instead of universally unique identifier (UUID) values for the root and resume parameters. Site Recovery requires UUIDs because device names tin can change. Upon restart, a VM might not come up with the same proper noun on failover, resulting in problems.
The post-obit examples are lines from GRUB files where device names appear instead of the required UUIDs:
-
File /kick/grub2/grub.cfg:
linux /boot/vmlinuz-3.12.49-11-default root=/dev/sda2 ${extra_cmdline} resume=/dev/sda1 splash=silent quiet showopts -
File: /boot/grub/carte.lst
kernel /boot/vmlinuz-3.0.101-63-default root=/dev/sda2 resume=/dev/sda1 splash=silent crashkernel=256M-:128M showopts vga=0x314
Ready the problem
Replace each device name with the corresponding UUID:
-
Find the UUID of the device by executing the command
blkid <device name>. For case:blkid /dev/sda1 /dev/sda1: UUID="6f614b44-433b-431b-9ca1-4dd2f6f74f6b" Blazon="bandy" blkid /dev/sda2 /dev/sda2: UUID="62927e85-f7ba-40bc-9993-cc1feeb191e4" TYPE="ext3" -
Replace the device name with its UUID, in the formats
root=UUID=<UUID>andresume=UUID=<UUID>. For example, after replacement, the line from /boot/chow/bill of fare.lst would look like the following line:kernel /kicking/vmlinuz-3.0.101-63-default root=UUID=62927e85-f7ba-40bc-9993-cc1feeb191e4 resume=UUID=6f614b44-433b-431b-9ca1-4dd2f6f74f6b splash=silent crashkernel=256M-:128M showopts vga=0x314 -
Retry the protection.
Protection failed because GRUB device doesn't exist (error code 151124)
Possible cause
The Chow configuration files (/kick/grub/card.lst, /kicking/grub/grub.cfg, /boot/grub2/grub.cfg, or /etc/default/grub) might contain the parameters rd.lvm.lv or rd_LVM_LV. These parameters identify the Logical Volume Managing director (LVM) devices that are to be discovered at kicking time. If these LVM devices don't exist, the protected system itself won't kick and will exist stuck in the boot process. The same problem volition as well exist seen with the failover VM. Hither are few examples:
-
File: /boot/grub2/chow.cfg on RHEL7:
linux16 /vmlinuz-three.10.0-957.el7.x86_64 root=/dev/mapper/rhel_mup--rhel7u6-root ro crashkernel=128M\@64M rd.lvm.lv=rootvg/root rd.lvm.lv=rootvg/swap rhgb tranquillity LANG=en_US.UTF-eight -
File: /etc/default/grub on RHEL7:
GRUB_CMDLINE_LINUX="crashkernel=car rd.lvm.lv=rootvg/root rd.lvm.lv=rootvg/swap rhgb repose -
File: /boot/grub/menu.lst on RHEL6:
kernel /vmlinuz-2.6.32-754.el6.x86_64 ro root=UUID=36dd8b45-e90d-40d6-81ac-ad0d0725d69e rd_NO_LUKS LANG=en_US.UTF-8 rd_NO_MD SYSFONT=latarcyrheb-sun16 crashkernel=auto rd_LVM_LV=rootvg/lv_root KEYBOARDTYPE=pc KEYTABLE=us rd_LVM_LV=rootvg/lv_swap rd_NO_DM rhgb serenity
In each example, Grub has to detect ii LVM devices with the names root and swap from the volume group rootvg.
Fix the problem
If the LVM device doesn't exist, either create it or remove the corresponding parameters from the GRUB configuration files. So, try again to enable protection.
Mobility service update finished with warnings (error lawmaking 151083)
The Site Recovery Mobility service has many components, one of which is called the filter driver. The filter driver is loaded into system retentiveness only during arrangement restart. Whenever a Mobility service update includes filter driver changes, the machine is updated but yous yet see a warning that some fixes crave a restart. The warning appears because the filter commuter fixes can take effect only when the new filter driver is loaded, which happens merely during a restart.
Note
This is only a alert. The existing replication continues to piece of work even later on the new agent update. You tin can cull to restart whenever y'all want the benefits of the new filter driver, but the old filter driver keeps working if you don't restart.
Apart from the filter driver, the benefits of whatsoever other enhancements and fixes in the Mobility service update take issue without requiring a restart.
Protection not enabled if replica managed disk exists
This error occurs when the replica managed disk already exists, without expected tags, in the target resource group.
Possible cause
This problem can occur if the virtual automobile was previously protected, and when replication was disabled, the replica disk wasn't removed.
Fix the trouble
Delete the replica disk identified in the error bulletin and retry the failed protection chore.
Enable protection failed equally the installer is unable to find the root disk (error code 151137)
This error occurs for Linux machines where the Bone disk is encrypted using Azure Disk Encryption (ADE). This is a valid issue in Agent version 9.35 only.
Possible Causes
The installer is unable to find the root disk that hosts the root file-arrangement.
Fix the problem
Perform the post-obit steps to fix this upshot.
-
Detect the amanuensis $.25 nether the directory /var/lib/waagent on RHEL and CentOS machines using the below control:
# find /var/lib/ -proper name Micro\*.gzExpected output:
/var/lib/waagent/Microsoft.Azure.RecoveryServices.SiteRecovery.LinuxRHEL7-i.0.0.9139/UnifiedAgent/Microsoft-ASR_UA_9.35.0.0_RHEL7-64_GA_30Jun2020_release.tar.gz -
Create a new directory and change the directory to this new directory.
-
Extract the Agent file found in the first stride here, using the beneath command:
tar -xf <Tar Ball File> -
Open the file prereq_check_installer.json and delete the following lines. Save the file after that.
{ "CheckName": "SystemDiskAvailable", "CheckType": "MobilityService" }, -
Invoke the installer using the control:
./install -d /usr/local/ASR -r MS -q -v Azure -
If the installer succeeds, retry the enable replication job.
Adjacent steps
Replicate Azure VMs to another Azure region
Feedback
Submit and view feedback for
Source: https://docs.microsoft.com/en-us/azure/site-recovery/azure-to-azure-troubleshoot-errors
0 Response to "Debian a Problem Has Ocurred and the Systems Cant Recover Please Log Our and Try Again"
Post a Comment